Rethinking Investment Time Horizons
 Imagine investing $1,000 in a stock and watching it grow to $100,000. It may sound like a pipe dream, but according to two books, "100 to 1 in the Stock Market" by Thomas William Phelps and "100 Baggers: Stocks That Return 100-to-1 and How To Find Them" by Christopher W. Mayer, this type of extraordinary return is not only possible but has occurred more frequently than one might expect.
Imagine investing $1,000 in a stock and watching it grow to $100,000. It may sound like a pipe dream, but according to two books, "100 to 1 in the Stock Market" by Thomas William Phelps and "100 Baggers: Stocks That Return 100-to-1 and How To Find Them" by Christopher W. Mayer, this type of extraordinary return is not only possible but has occurred more frequently than one might expect.
Phelps' classic work, first published in 1972, presents a compelling case for the existence of "centibaggers" - stocks that return 100 times the initial investment. His book laid the foundation for the study of these incredible investments and provided insights into the characteristics that set them apart from the rest of the market.
Fast forward to 2015, and Christopher W. Mayer's "100 Baggers" expands upon Phelps' work, diving deeper into the concept of stocks that return 100-to-1. Mayer's book offers modern case studies, updated strategies, and a fresh perspective on identifying these elusive investment opportunities.
Both authors emphasize the importance of factors such as strong leadership, sustainable competitive advantages, and significant growth potential in identifying potential centibaggers. They also stress the need for investors to conduct thorough research, maintain a long-term mindset, and have the patience to weather short-term volatility.
While the pursuit of 100-to-1 returns is not without risk, Phelps and Mayer argue that investors who understand the key characteristics and strategies for identifying these stocks can greatly improve their chances of success. Their books serve as valuable guides for those seeking to uncover the market's hidden gems.
In this write-up, we'll explore the key ideas and strategies presented in both "100 to 1 in the Stock Market" and "100 Baggers," compare and contrast the authors' approaches, and discuss how investors can apply these lessons to their own investment strategies. By understanding the wisdom shared in these two influential works, investors can gain valuable insights into the pursuit of extraordinary returns in the stock market.
The Concept of 100 Baggers
A "100 bagger" is a stock that increases in value by 100 times the initial investment. For example, if you invested $1,000 in a stock and its value rose to $100,000, that stock would be considered a 100 bagger. This term was popularized by Thomas William Phelps in his 1972 book "100 to 1 in the Stock Market" and later expanded upon by Christopher W. Mayer in his 2015 book "100 Baggers."
Historical examples of 100 baggers
Throughout history, there have been numerous examples of stocks that have achieved 100 bagger status. Some notable examples include:
- Berkshire Hathaway: Under the leadership of Warren Buffett, Berkshire Hathaway has grown from around $19 per share in 1965 to over $600,000 per share in 2024, representing a return of more than 2,000,000%.
- Monster Beverage: Monster Beverage (formerly Hansen Natural) saw its stock price increase from around $0.08 per share in 1995 to over $80 per share in 2015, a 100,000% return.
- Amazon: Amazon's stock price has grown from $1.50 per share during its IPO in 1997 to over $3,000 per share in 2021, a return of more than 200,000%.
- Apple: Apple's stock has risen from a split-adjusted IPO price of $0.10 in 1980 to over $165 per share in 2024, a return of more than 140,000%.
Both Phelps and Mayer highlight these and other examples to illustrate the potential for extraordinary returns in the stock market. While 100 baggers are rare, they are not impossible to find, and investors who are willing to put in the effort and exercise patience can greatly increase their chances of identifying these lucrative opportunities. The two of them also emphasize the importance of maintaining a long-term perspective and avoiding the temptation to trade in and out of positions based on short-term market fluctuations. In reality, most people are not patient enough to hold onto a stock for the long term, and they end up selling too soon. This is why it is important to have a long-term mindset and the patience to weather short-term volatility.
The power of compounding returns The concept of 100 baggers highlights the incredible power of compounding returns over time. When a stock consistently delivers high returns year after year, the compounding effect can lead to astronomical growth in value.
To illustrate, consider an investment that grows at an annual rate of 20%. After 25 years, the initial investment would be worth 95 times the starting value. If that same investment grew at a 26% annual rate, it would take only 20 years to achieve a 100 bagger return.
The power of compounding underscores the importance of identifying stocks with strong, sustainable growth potential and holding them for the long term. By allowing investments to compound over time, investors can potentially turn relatively small initial investments into substantial sums.
However, it's crucial to recognize that achieving 100 bagger returns is not easy and requires a combination of skill, research, and patience. In the following sections, we'll explore the key characteristics of 100 baggers and strategies for identifying these rare and lucrative investment opportunities.
Key Characteristics of 100 Baggers
Both Thomas William Phelps and Christopher W. Mayer have identified several key characteristics that are common among stocks that achieve 100 bagger returns. By understanding these attributes, investors can better position themselves to identify potential 100 baggers in the market.
A. Strong, visionary leadership One of the most critical factors in a company's long-term success is the presence of strong, visionary leadership. 100 bagger companies are often led by exceptional managers who have a clear understanding of their industry, a compelling vision for the future, and the ability to execute their strategies effectively.
These leaders are able to navigate their companies through challenges, adapt to changing market conditions, and capitalize on new opportunities. They are also skilled at communicating their vision to employees, investors, and other stakeholders, creating a strong sense of purpose and alignment throughout the organization.
B. Sustainable competitive advantages Another key characteristic of 100 baggers is the presence of sustainable competitive advantages, or "moats." These are the unique qualities that allow a company to maintain its edge over competitors and protect its market share over time.
Some examples of competitive advantages include:
- Network effects: The more users a product or service has, the more valuable it becomes (e.g., social media platforms).
- Economies of scale: Larger companies can produce goods or services more efficiently and at lower costs than smaller competitors.
- Brand loyalty: Strong brand recognition and customer loyalty can create a barrier to entry for competitors.
- Intellectual property: Patents, trademarks, and other proprietary technologies can give a company a significant advantage.
Companies with strong, sustainable competitive advantages are better positioned to maintain their growth and profitability over the long term, making them more likely to become 100 baggers.
C. Robust growth potential To achieve 100 bagger returns, a company must have significant growth potential. This can come from a variety of sources, such as: 1. Expanding into new markets or geographies 2. Introducing new products or services 3. Increasing market share in existing markets 4. Benefiting from industry tailwinds or secular growth trends
Investors should look for companies with a large addressable market, a proven ability to innovate, and a track record of consistent growth. Companies that can grow their earnings and cash flow at high rates over an extended period are more likely to become 100 baggers.

D. Attractive valuation Finally, to maximize the potential for 100 bagger returns, investors should seek out companies that are trading at attractive valuations relative to their growth potential. This means looking for stocks that are undervalued by the market or have yet to be fully appreciated by other investors.
One way to identify potentially undervalued stocks is to look for companies with low price-to-earnings (P/E) ratios relative to their growth rates. Another approach is to look for companies with strong fundamentals and growth prospects that are trading at a discount to their intrinsic value.
By combining the search for strong, visionary leadership, sustainable competitive advantages, robust growth potential, and attractive valuations, investors can increase their chances of uncovering potential 100 baggers in the market. However, it's important to remember that identifying these stocks requires thorough research, due diligence, and a long-term investment horizon.
Strategies for Finding Potential 100 Baggers
While identifying potential 100 baggers is no easy task, there are several strategies investors can employ to increase their chances of success. By combining thorough research, a focus on smaller companies, an understanding of long-term trends, and a patient, long-term mindset, investors can position themselves to uncover the market's hidden gems.
A. Conducting thorough research and due diligence One of the most critical strategies for finding potential 100 baggers is to conduct extensive research and due diligence. This involves going beyond surface-level financial metrics and digging deep into a company's business model, competitive landscape, management team, and growth prospects.
Some key areas to focus on when researching potential 100 baggers include:
- Financial statements: Look for companies with strong and consistent revenue growth, high margins, and robust cash flow generation.
- Management team: Assess the quality and track record of the company's leadership, paying particular attention to their vision, strategy, and ability to execute.
- Competitive advantages: Identify the unique qualities that set the company apart from its competitors and give it a lasting edge in the market.
- Industry dynamics: Understand the larger trends and forces shaping the company's industry, and look for companies positioned to benefit from these tailwinds.
By conducting thorough research and due diligence, investors can gain a deeper understanding of a company's true potential and make more informed investment decisions.
B. Focusing on smaller, lesser-known companies Another key strategy for finding potential 100 baggers is to focus on smaller, lesser-known companies. These companies are often overlooked by larger investors and analysts, creating opportunities for value-oriented investors to get in on the ground floor of a potential winner.
Smaller companies may have more room for growth than their larger counterparts, as they can expand into new markets, introduce new products, or gain market share more easily. They may also be more agile and adaptable to changing market conditions, allowing them to capitalize on new opportunities more quickly.
However, investing in smaller companies also comes with increased risk, as these firms may have less access to capital, fewer resources, and a shorter track record of success. As such, investors must be particularly diligent in their research and analysis when considering smaller, lesser-known companies.
C. Identifying long-term trends and industry tailwinds
To find potential 100 baggers, investors should also focus on identifying long-term trends and industry tailwinds that can drive sustained growth over time. These trends can come from a variety of sources, such as:
- Demographic shifts: Changes in population size, age structure, or consumer preferences can create new opportunities for companies in certain industries.
- Technological advancements: The emergence of new technologies can disrupt existing industries and create new markets for innovative companies to exploit.
- Regulatory changes: Changes in government policies or regulations can create new opportunities or challenges for companies in affected industries.
By identifying and understanding these long-term trends, investors can position themselves to benefit from the companies best positioned to capitalize on these tailwinds.
D. Patience and long-term mindset Finally, one of the most essential strategies for finding potential 100 baggers is to maintain a patient, long-term mindset. Building a 100 bagger takes time, often decades, and investors must be willing to hold onto their investments through short-term volatility and market fluctuations.
This requires a deep conviction in the underlying business and its long-term prospects, as well as the discipline to resist the temptation to sell too early. Investors should approach potential 100 baggers as long-term business owners rather than short-term traders and be prepared to weather the ups and downs of the market over time.
By combining thorough research, a focus on smaller companies, an understanding of long-term trends, and a patient, long-term mindset, investors can increase their chances of uncovering the market's most promising opportunities and achieving the outsized returns associated with 100 bagger investments.
Case Studies from the Book
 In "100 Baggers," Christopher W. Mayer presents several case studies of companies that have achieved 100-to-1 returns for their investors. These real-world examples provide valuable insights into the characteristics and strategies that have contributed to these remarkable success stories.
In "100 Baggers," Christopher W. Mayer presents several case studies of companies that have achieved 100-to-1 returns for their investors. These real-world examples provide valuable insights into the characteristics and strategies that have contributed to these remarkable success stories.
A. Overview of a few notable 100 bagger examples from the books
- Monster Beverage: Originally known as Hansen Natural, this company focused on selling natural sodas and juices. However, their introduction of the Monster Energy drink in 2002 catapulted the company to new heights. From 1995 to 2015, Monster Beverage's stock price increased by a staggering 100,000%, turning a $10,000 investment into $10 million.
- Altria Group: Formerly known as Philip Morris, Altria Group is a tobacco company that has delivered consistent returns for investors over the long term. Despite facing challenges such as litigation and declining smoking rates, Altria has adapted and diversified its business, resulting in a return of more than 100,000% from 1968 to 2015.
- Walmart: Founded by Sam Walton in 1962, Walmart has grown from a single discount store in Arkansas to the world's largest retailer. By focusing on low prices, efficient operations, and strategic expansion, Walmart has delivered returns of more than 100,000% since its IPO in 1970.
- Pfizer: Phelps noted that an investment of $1,000 in Pfizer in 1942 would have grown to $102,000 by 1962, representing a 100-fold increase.
- Chrysler: An investment of $1,000 in Chrysler in 1932 would have grown to $271,000 by 1952, a return of more than 200 times the initial investment.
- Coca-Cola: A $1,000 investment in Coca-Cola in 1919 would have grown to $126,000 by 1939, a return of more than 100 times.
- Sears, Roebuck and Co.: An investment of $1,000 in Sears in 1922 would have grown to $175,000 by 1942, representing a return of 175 times the initial investment.
- Merck & Co.: a $1,000 investment in Merck & Co. in 1930 would have grown to $160,000 by 1950, a return of 160 times the initial investment.
It is not lost on me that Sears, Roebuck and Co. is now bankrupt and Chrysler got swallowed by Fiat which in turn became Stellantis. This is a reminder that past performance is not indicative of future results. It is also a reminder that the market is not always efficient. It is also a reminder that the market is not always rational. It is also a reminder that the market is not always right.
B. Lessons learned from these success stories
- Focus on long-term growth: Each of these companies had a clear vision for long-term growth and remained committed to their strategies over time.
- Adapt to changing market conditions: Whether it was Monster Beverage's pivot to energy drinks or Altria's diversification into new product categories, these companies demonstrated an ability to adapt to changing market conditions and consumer preferences. As an aside, I was an Altria shareholder for years. It was not until their botched investment into JUUL Labs, Inc. and subsequent opinion that vaping just might not be able to generate the returns of the bygone days of Big Tobacco that I sold my entire position.
- Maintain a competitive edge: Walmart's relentless focus on low prices and efficient operations allowed it to maintain a competitive advantage over its rivals and continue growing over time.
- >Reinvest in the business: These companies consistently reinvested their profits into the business, funding new growth initiatives, expanding into new markets, and improving their operations.
C. How readers can apply these lessons in their own investing
- Identify companies with clear growth strategies: Look for companies that have a well-defined vision for long-term growth and a track record of executing on their plans.
- Assess adaptability: Consider how well a company is positioned to adapt to changing market conditions and consumer preferences over time.
- Evaluate competitive advantages: Seek out companies with strong and sustainable competitive advantages that can help them maintain their edge in the market.
- Analyze capital allocation: Pay attention to how a company allocates its capital, looking for firms that reinvest in the business and pursue high-return opportunities.
- Maintain a long-term perspective: As these case studies demonstrate, building a 100 bagger takes time. Investors must be patient and maintain a long-term outlook, even in the face of short-term volatility or market uncertainty.
 By studying the success stories presented in "100 Baggers," readers can gain valuable insights into the characteristics and strategies that have contributed to these remarkable investment outcomes. By applying these lessons to their own investment approach, investors can improve their chances of identifying and profiting from the next generation of 100 bagger opportunities.
By studying the success stories presented in "100 Baggers," readers can gain valuable insights into the characteristics and strategies that have contributed to these remarkable investment outcomes. By applying these lessons to their own investment approach, investors can improve their chances of identifying and profiting from the next generation of 100 bagger opportunities.
Criticisms and Risks
While the pursuit of 100 bagger investments can be an exciting and potentially lucrative endeavor, it is important to acknowledge the challenges and risks associated with this approach. By understanding the limitations and potential counterarguments to the strategies presented in "100 Baggers," investors can make more informed decisions and better manage their risk.
A. Acknowledge the challenges and risks of seeking 100 baggers
- Rarity: 100 baggers are, by definition, rare and exceptional investments. The vast majority of stocks will not achieve this level of returns, and identifying these opportunities requires significant skill, research, and luck.
- Volatility: Companies with the potential for 100 bagger returns are often smaller, less established firms with higher levels of volatility and risk. Investors must be prepared for significant ups and downs along the way.
- Time horizon: Building a 100 bagger takes time, often decades. Investors must have the patience and discipline to hold onto their investments through market cycles and short-term fluctuations.
- Survivorship bias: It is important to note that the case studies presented in "100 Baggers" represent the success stories, and there are countless other companies that have failed or underperformed over time. Investors must be aware of survivorship bias when evaluating historical examples of 100 baggers.
B. Potential counterarguments or limitations of the books' approaches
- Market efficiency: Some critics argue that the market is largely efficient and that consistently identifying undervalued stocks is difficult, if not impossible. They contend that the success stories presented in the book are more a result of luck than skill.
- Hindsight bias: It is easier to identify the characteristics of successful investments after the fact than it is to predict them in advance. Critics may argue that the book's approach is more useful for explaining past successes than for identifying future opportunities.
- Changing market dynamics: The strategies that have worked in the past may not be as effective in the future, as market conditions, industry dynamics, and investor behavior evolve over time.
C. Importance of diversification and risk management
- Diversification: Given the high level of risk associated with pursuing 100 baggers, investors must diversify their portfolios across multiple stocks, sectors, and asset classes. By spreading their bets, investors can mitigate the impact of any single investment that fails to meet expectations. Mayer actually suggests that investors should have a concentrated portfolio of stocks. He argues that by concentrating efforts on fewer stocks, his thinking is you should have fewer disappointments.
- Risk tolerance: Investors must honestly assess their own risk tolerance and investment objectives, recognizing that the pursuit of 100 baggers may not be suitable for everyone.
While the strategies presented in "100 Baggers" offer a compelling framework for identifying high-potential investment opportunities, investors must remain aware of the challenges and risks associated with this approach. By acknowledging the limitations, maintaining a diversified portfolio, and implementing sound risk management practices, investors can increase their chances of success while mitigating the potential downside of pursuing 100 bagger investments.
Personal Takeaways and Recommendations
After reading "100 Baggers" by Christopher W. Mayer and "100 to 1 in the Stock Market" by Thomas William Phelps, I feel I have gained valuable insights into the characteristics and strategies associated with some of the most successful investments in history. These books have not only provided a compelling framework for identifying potential 100 baggers but have also reinforced the importance of a long-term, patient approach to investing.
A. Learnings from the book
- The power of compounding: The case studies presented in these books demonstrate the incredible power of compounding returns over time. By identifying companies with strong growth potential and holding onto them for the long term, investors can achieve outsized returns that far exceed the market average.
- The importance of quality: Successful 100 bagger investments often share common characteristics, such as strong management teams, sustainable competitive advantages, and robust growth prospects. By focusing on high-quality companies with these attributes, investors can increase their chances of success.
- The value of patience: Building a 100 bagger takes time, often decades. These books have reinforced the importance of maintaining a long-term perspective and having the patience to hold onto investments through short-term volatility and market fluctuations.
- The benefits of independent thinking: Many of the most successful 100 bagger investments were initially overlooked or misunderstood by the broader market. These books have encouraged me to think independently, conduct my own research, and be willing to go against the crowd when necessary.
- Focus on quality: I plan to place a greater emphasis on identifying high-quality companies with strong management teams, sustainable competitive advantages, and robust growth prospects.
- Conduct thorough research: I will dedicate more time and effort to conducting thorough research and due diligence on potential investments, looking beyond surface-level financial metrics to gain a deeper understanding of a company's business model, competitive landscape, and long-term potential.
- Maintain a long-term perspective: I will strive to maintain a long-term perspective with my investments, resisting the temptation to trade in and out of positions based on short-term market movements or emotions.
- Diversify and manage risk: While pursuing potential 100 baggers, I will continue to diversify my portfolio across multiple stocks, sectors, and asset classes, and implement sound risk management practices to protect against downside risk.
C. Why would I recommend these books to others
- Valuable insights: "100 Baggers" and "100 to 1 in the Stock Market" offer valuable insights into the characteristics and strategies associated with some of the most successful investments in history. By studying these examples, readers can gain a deeper understanding of what it takes to identify and profit from high-potential investment opportunities.
- Engaging and accessible: Both books are well-written and engaging, presenting complex investment concepts in an accessible and easy-to-understand manner. They strike a good balance between theory and practical application, making them suitable for both novice and experienced investors.
- Long-term perspective: These books promote a long-term, patient approach to investing that is often lacking in today's fast-paced, short-term oriented market environment. By encouraging readers to think like business owners and focus on the long-term potential of their investments, these books can help investors avoid common pitfalls and achieve better outcomes.
- Inspiration and motivation: The case studies and success stories presented in these books can serve as a source of inspiration and motivation for investors, demonstrating what is possible with a disciplined, long-term approach to investing.
While "100 Baggers" and "100 to 1 in the Stock Market" are not without their limitations and potential criticisms, I believe they offer valuable insights and strategies that can benefit investors of all levels. By incorporating the key lessons from these books into a well-diversified, risk-managed investment approach, investors can improve their chances of identifying and profiting from the next generation of 100 bagger opportunities.
Conclusion
Throughout this write-up, we have explored the concept of 100 baggers and the key lessons presented in Christopher W. Mayer's "100 Baggers" and Thomas William Phelps' "100 to 1 in the Stock Market." These books offer valuable insights into the characteristics and strategies associated with some of the most successful investments in history, providing a roadmap for investors seeking to identify and profit from high-potential opportunities.
A. Recapping the main points about 100 baggers and key lessons
- 100 baggers are rare and exceptional investments that generate returns of 100 times or more over the long term.
- These investments often share common characteristics, such as strong management teams, sustainable competitive advantages, robust growth prospects, and attractive valuations.
- To identify potential 100 baggers, investors must conduct thorough research, focus on smaller and lesser-known companies, identify long-term trends and industry tailwinds, and maintain a patient, long-term mindset.
- >The case studies presented in these books demonstrate the power of compounding returns and the importance of thinking like a business owner rather than a short-term trader.
B. The potential rewards and risks of this investment approach
- Potential rewards: Investing in 100 baggers can generate life-changing returns, far exceeding the market average and providing financial security for investors and their families.
- Potential risks: The pursuit of 100 baggers is not without risk, as these investments are often associated with higher levels of volatility, uncertainty, and potential for loss. Investors must be prepared for the possibility of underperformance or even complete loss of capital.
- Importance of diversification and risk management: To mitigate these risks, investors must maintain a well-diversified portfolio, implement sound risk management practices, and carefully consider the size of their positions in potential 100 baggers.
- Be prepared for the long haul: Building a 100 bagger takes time, often decades. Investors must have the patience and discipline to hold onto their investments through market cycles and short-term fluctuations. And along the way, there can be drops. NVIDIA, for example, dropped at least 50% three times in the last 25 years.
C. Do your own research and make informed decisions
- While "100 Baggers" and "100 to 1 in the Stock Market" offer valuable insights and strategies, they should not be viewed as a substitute for independent research and analysis.
- Investors must take responsibility for their own investment decisions, conducting thorough due diligence, evaluating multiple perspectives, and carefully considering their own financial goals and risk tolerance.
- The concepts and strategies presented in these books should be viewed as a starting point for further exploration and adaptation, rather than a one-size-fits-all approach to investing.
- By combining the lessons from these books with their own research and insights, investors can develop a personalized investment approach that aligns with their unique circumstances and objectives.
"100 Baggers" and "100 to 1 in the Stock Market" offer a compelling framework for identifying and profiting from high-potential investment opportunities. While the pursuit of 100 baggers is not without risk, investors who approach this strategy with a well-diversified, risk-managed, and long-term mindset stand to benefit from the incredible power of compounding returns over time. By studying the lessons presented in these books, conducting their own research, and making informed decisions, investors can position themselves for success in the ever-changing world of investing.
Final, final thought: in January of 2007, I founded an investment club. Fifth & Company Holdings. There were initially five members. By the time I motioned to wind down the businesses of the group in 2020, there were over ten members. Our first investment in early 2007 was ten shares of Deere & Company. We bought ten shares at $48.50 per share. We reinvested all of our dividends from 2007 until we sold in 2020. That was over four years ago. If we hadn't wound down the group, those shares would be worth well over $5,000. If there is one thing took away from Phelps and Mayer, it is if it is at all possible, hold onto your stocks for the long term.
 Recently, I purchased a
Recently, I purchased a  Delving into Burton G. Malkiel's
Delving into Burton G. Malkiel's 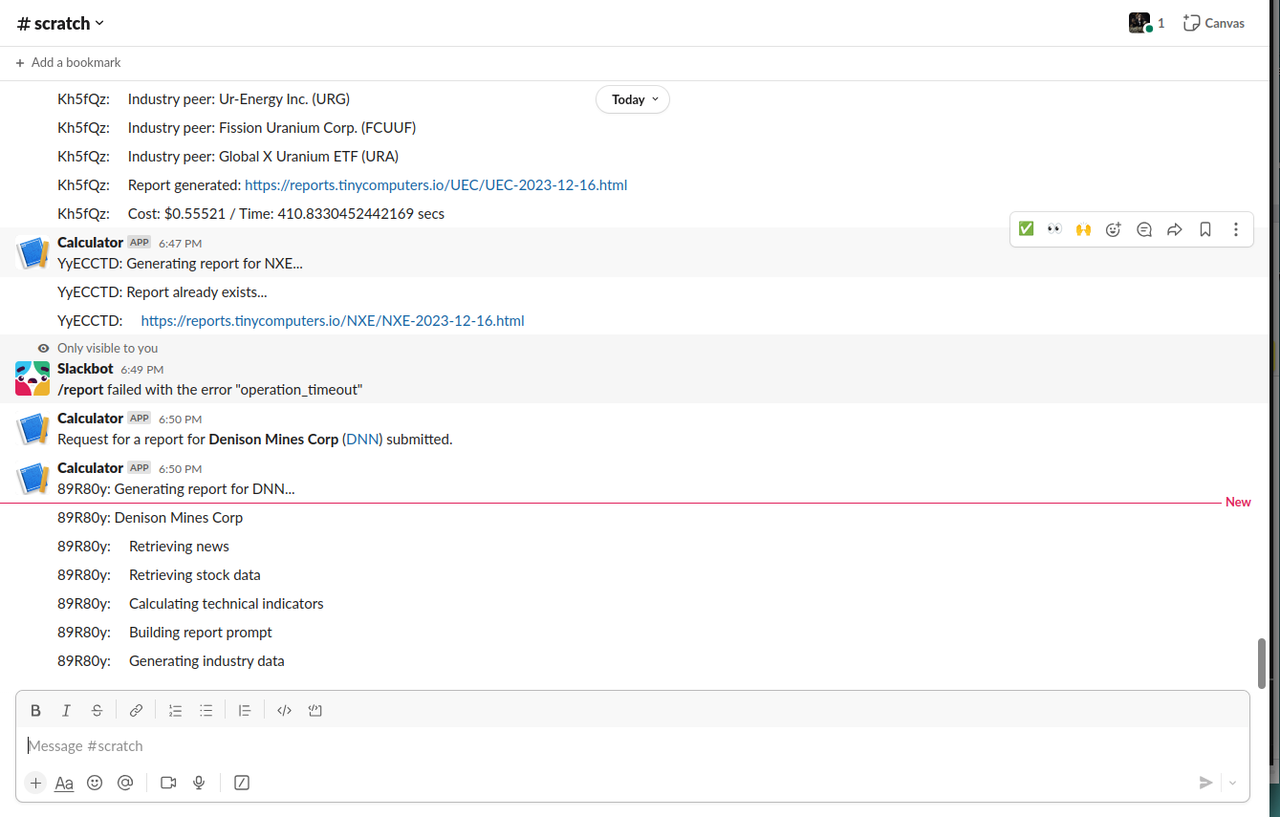 I've been playing around with Rust and Python lately. I've also been playing around with OpenAI's API. I thought it would be fun to combine all three and create a custom company stock report generator. I'm not a financial advisor, so don't take any of this as financial advice. I'm just having fun with some code.
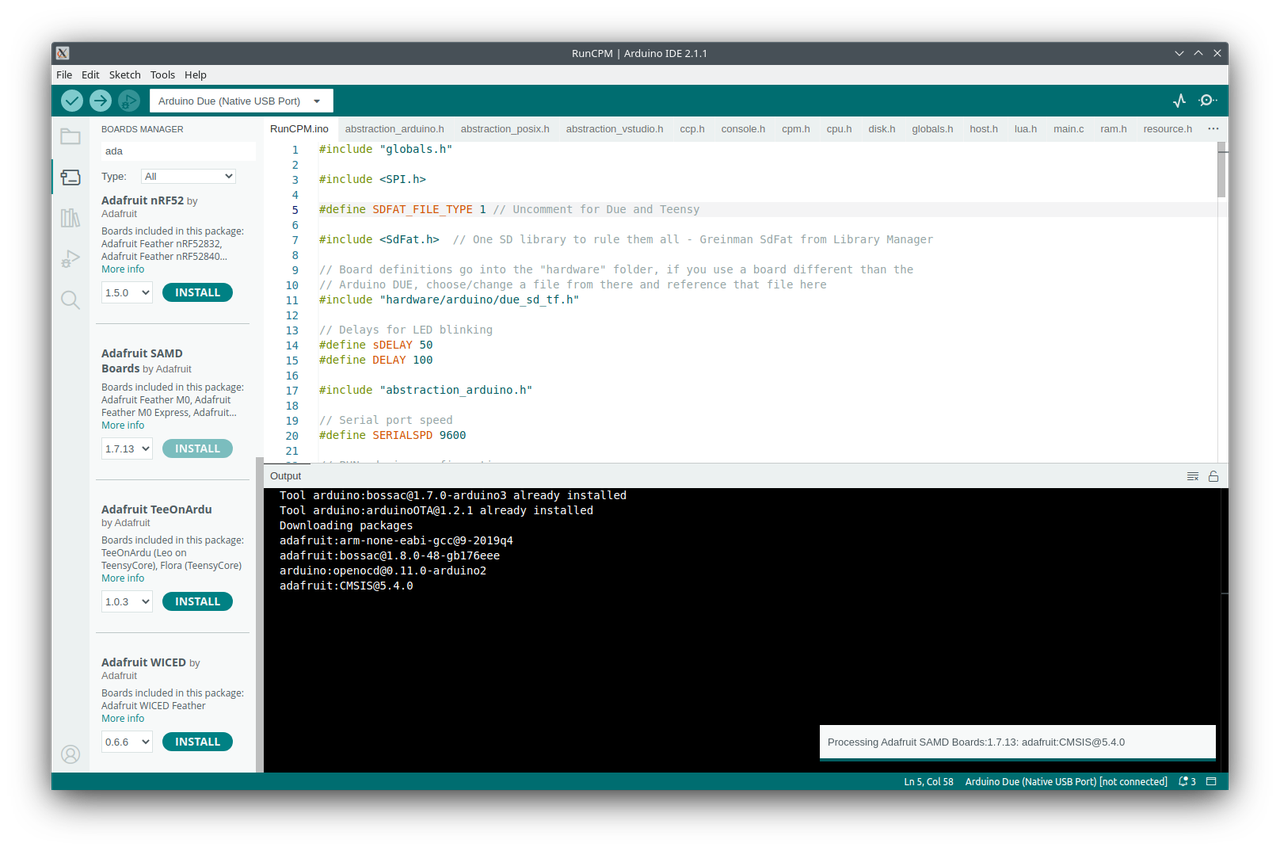
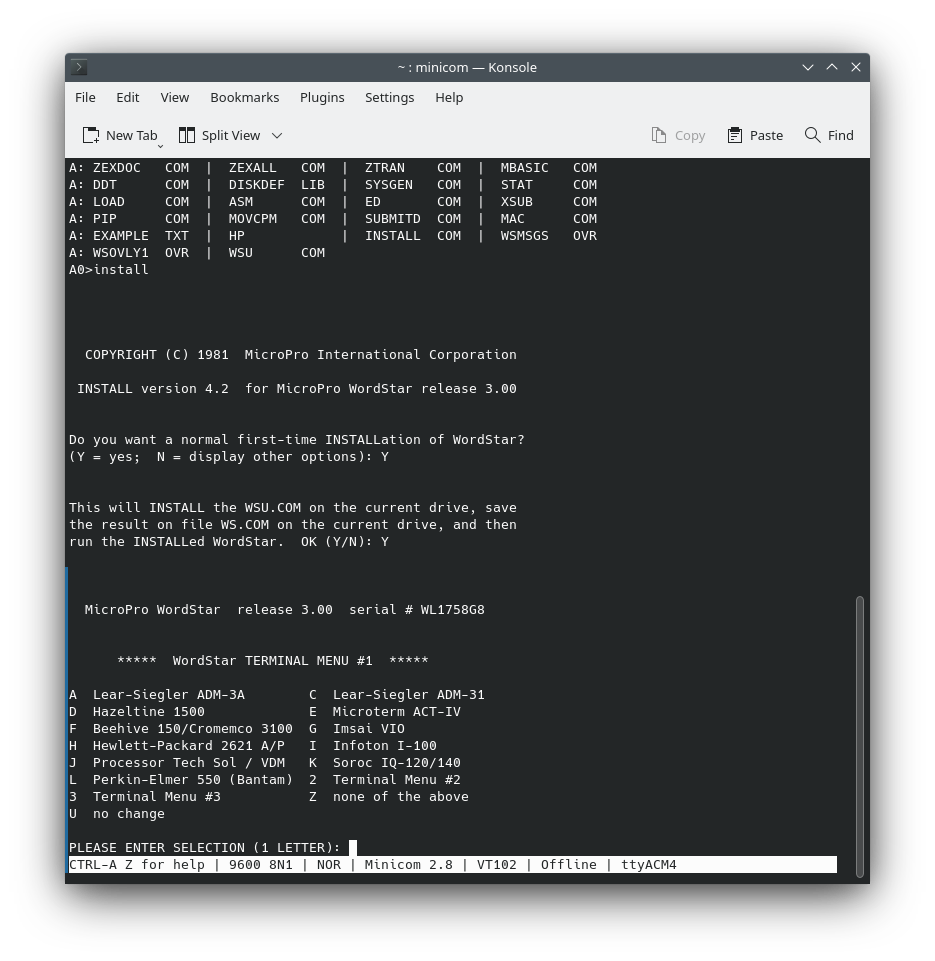
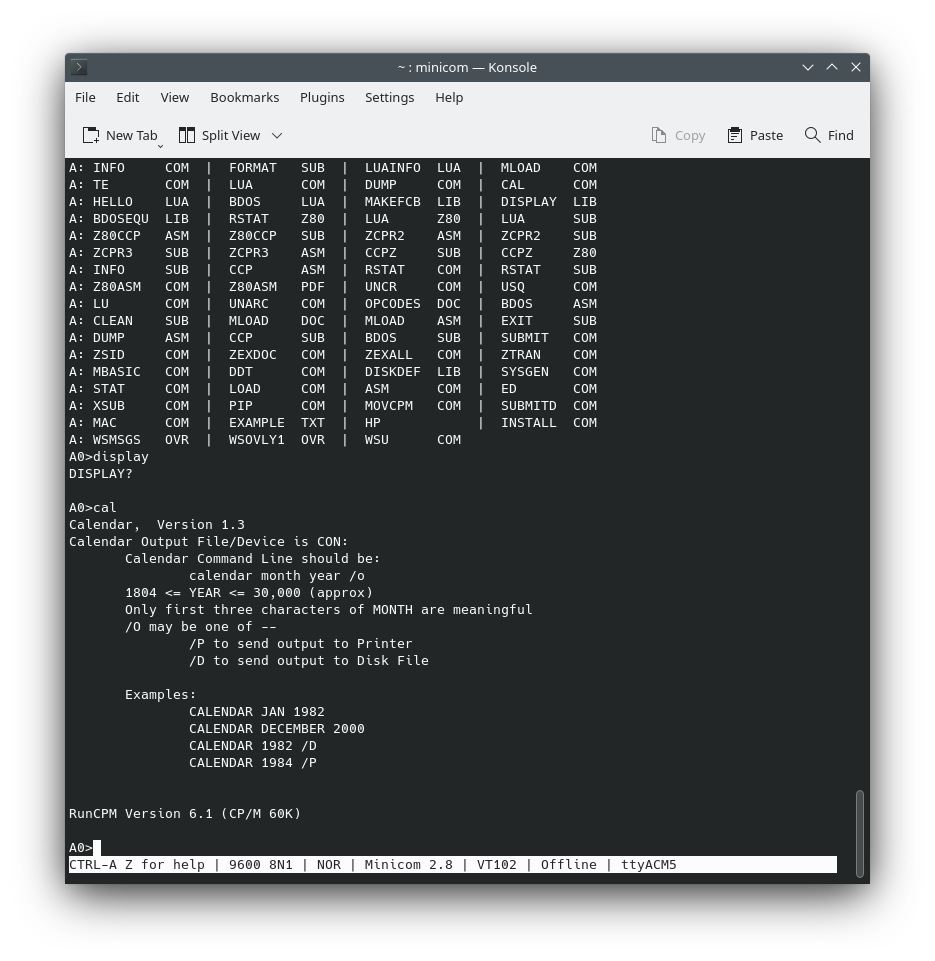
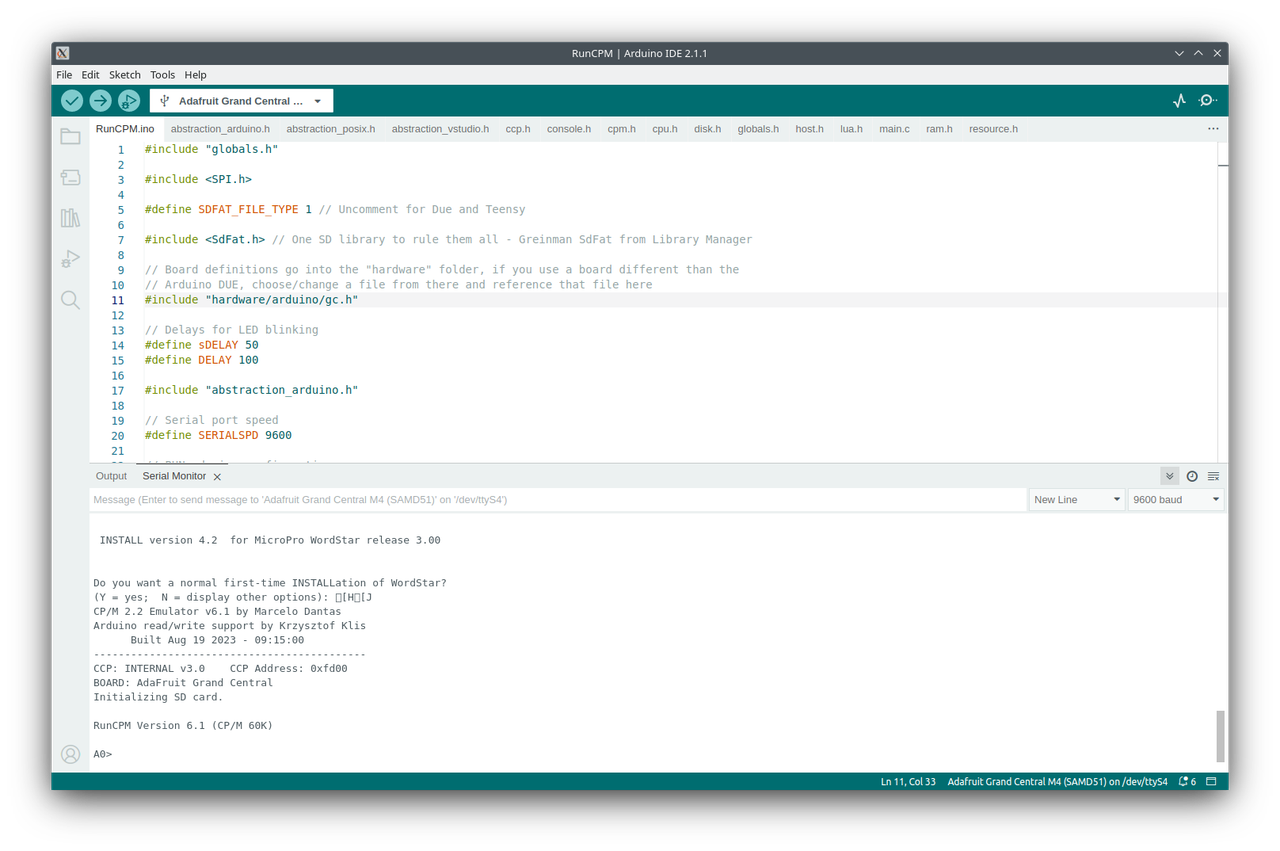
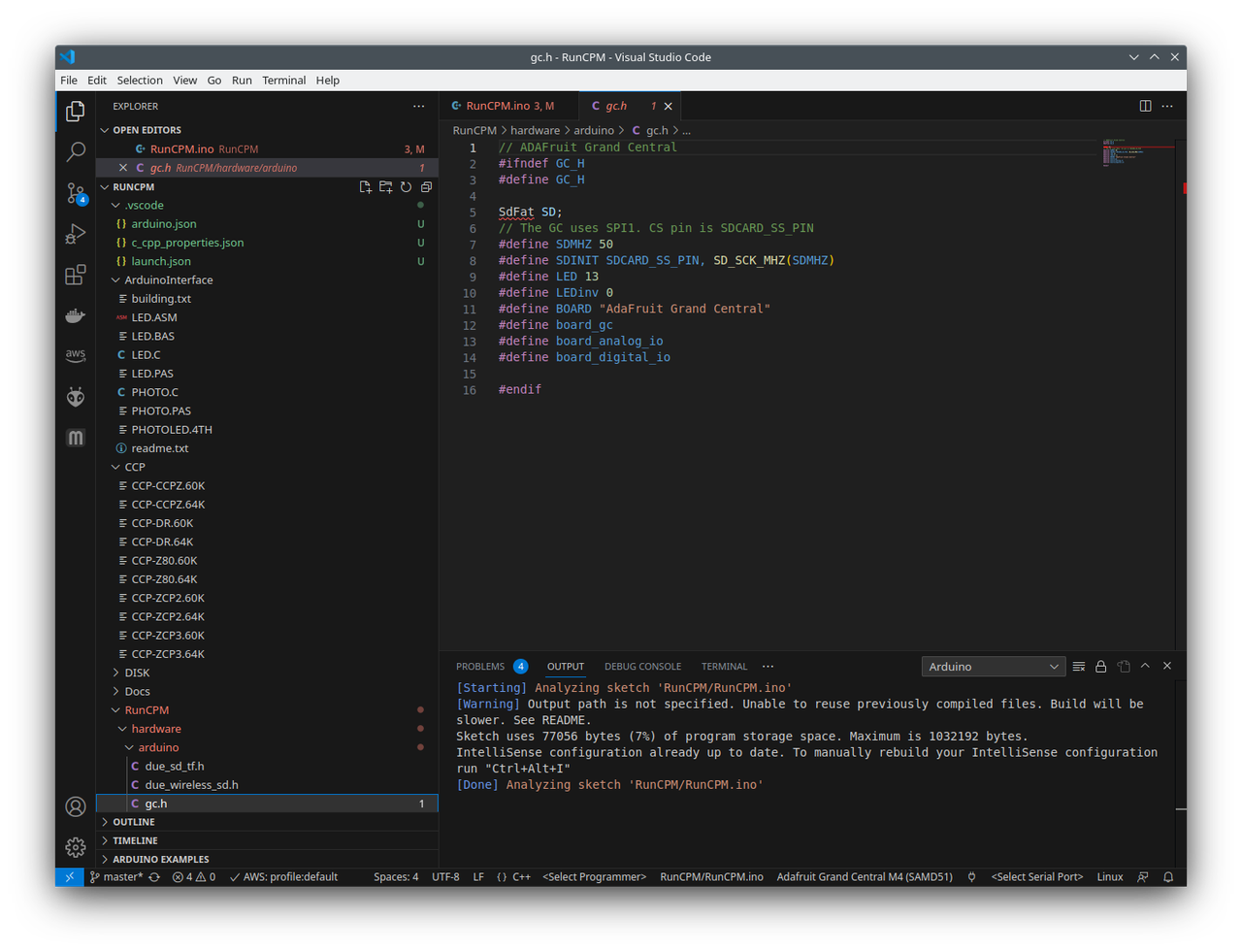
I've been playing around with Rust and Python lately. I've also been playing around with OpenAI's API. I thought it would be fun to combine all three and create a custom company stock report generator. I'm not a financial advisor, so don't take any of this as financial advice. I'm just having fun with some code. In today's world, where high-powered servers and multi-core processors are the norm, it's easy to overlook the importance of lightweight, efficient computing solutions. However, these solutions are vital in various domains such as embedded systems, IoT devices, and older hardware where resources are limited. Lightweight interpreters like Monty can make a significant difference in such environments.
In today's world, where high-powered servers and multi-core processors are the norm, it's easy to overlook the importance of lightweight, efficient computing solutions. However, these solutions are vital in various domains such as embedded systems, IoT devices, and older hardware where resources are limited. Lightweight interpreters like Monty can make a significant difference in such environments. The inherent stack-based nature of Reverse Polish Notation (RPN) significantly simplifies the parsing process in computational tasks. In traditional notations, complex parsing algorithms are often required to unambiguously determine the order of operations. However, in RPN, each operand is pushed onto a stack, and operators pop operands off this stack for computation. This eliminates the need for intricate parsing algorithms, thereby reducing the number of CPU cycles required for calculations. The streamlined parsing process ultimately contributes to more efficient code execution.
The inherent stack-based nature of Reverse Polish Notation (RPN) significantly simplifies the parsing process in computational tasks. In traditional notations, complex parsing algorithms are often required to unambiguously determine the order of operations. However, in RPN, each operand is pushed onto a stack, and operators pop operands off this stack for computation. This eliminates the need for intricate parsing algorithms, thereby reducing the number of CPU cycles required for calculations. The streamlined parsing process ultimately contributes to more efficient code execution. Monty is a character-based interpreter optimized for resource-constrained environments like embedded systems and IoT devices. It offers a rich set of features, including advanced terminal operations and stream-related functionalities. One of its key strengths lies in its minimalist design, which focuses on fast performance, readability, and ease of use. Monty uses well-known symbols for operations, making it easier for developers to adopt. Its design philosophy aims to offer a robust set of features without compromising on size and efficiency. The interpreter is also extensible, allowing for the addition of new features as required.
Monty is a character-based interpreter optimized for resource-constrained environments like embedded systems and IoT devices. It offers a rich set of features, including advanced terminal operations and stream-related functionalities. One of its key strengths lies in its minimalist design, which focuses on fast performance, readability, and ease of use. Monty uses well-known symbols for operations, making it easier for developers to adopt. Its design philosophy aims to offer a robust set of features without compromising on size and efficiency. The interpreter is also extensible, allowing for the addition of new features as required. The Z80 microprocessor, introduced in 1976 by Zilog, has an architecture that pairs well with Forth, particularly because of its efficient use of memory and registers. A typical Forth environment on the Z80 is initialized through a kernel, written in Z80 assembly language, which serves as the foundational layer. Upon this base, high-level Forth "words" or function calls are constructed, broadening the language's capabilities. Users can further extend these capabilities by defining their own "words" through a system called "colon definitions." The resulting definitions are stored in Forth's dictionary, a data structure that allows for quick look-up and execution of these custom words.
The Z80 microprocessor, introduced in 1976 by Zilog, has an architecture that pairs well with Forth, particularly because of its efficient use of memory and registers. A typical Forth environment on the Z80 is initialized through a kernel, written in Z80 assembly language, which serves as the foundational layer. Upon this base, high-level Forth "words" or function calls are constructed, broadening the language's capabilities. Users can further extend these capabilities by defining their own "words" through a system called "colon definitions." The resulting definitions are stored in Forth's dictionary, a data structure that allows for quick look-up and execution of these custom words.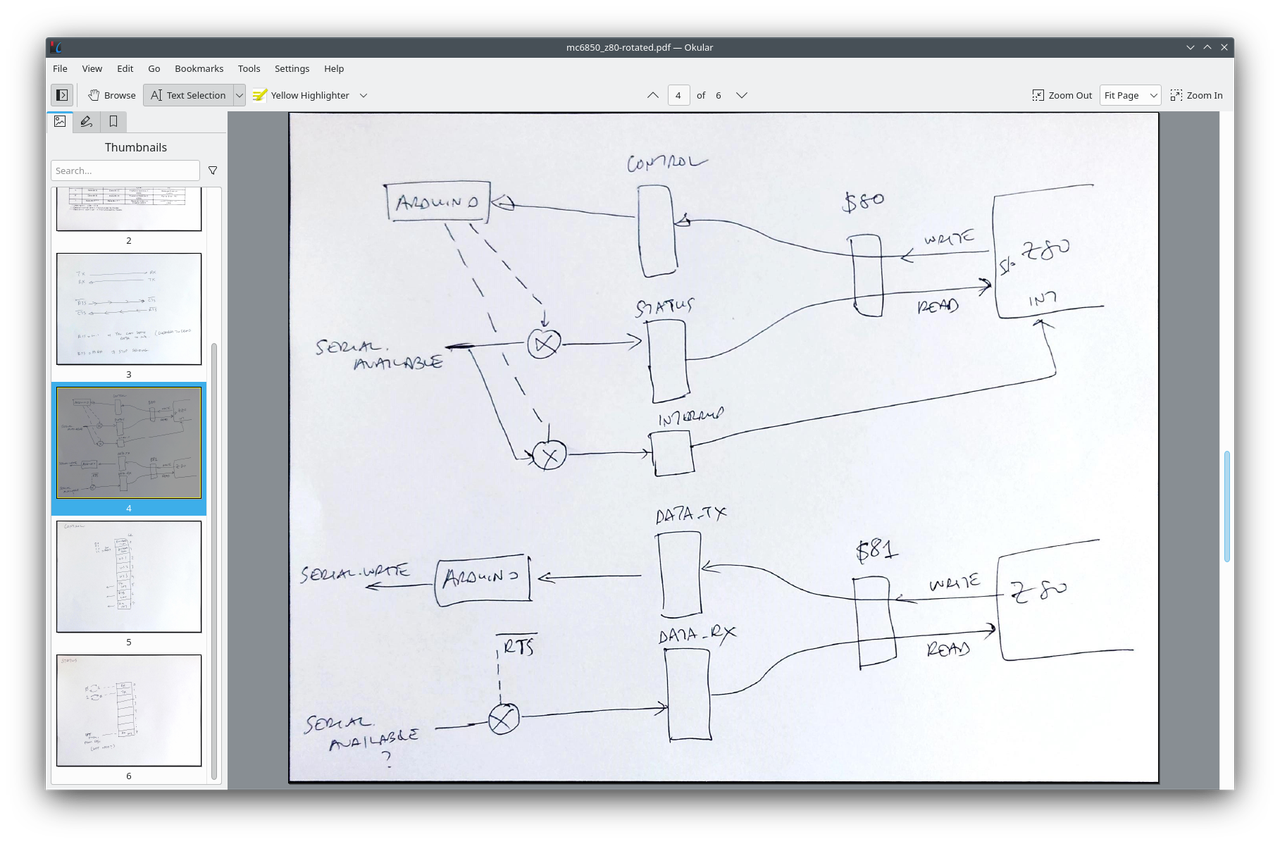
 The ACIA's status register uses an 8-bit configuration to manage various aspects of its behavior, ranging from interrupt requests to data carrier detection. Starting from the left-most bit, the IRQ (Interrupt Request) is set whenever the ACIA wants to interrupt the CPU. This can happen for several reasons, such as when the received data register is full, the transmitter data register is empty, or the !DCD bit is set. Next, the PE (Parity Error) is set if the received parity bit doesn't match the locally generated parity for incoming data. The OVRN (Receiver Overrun) bit is set when new data overwrites old data that hasn't been read by the CPU, indicating data loss. The FE (Framing Error) flag comes into play when the received data is not correctly framed by start and stop bits.
The ACIA's status register uses an 8-bit configuration to manage various aspects of its behavior, ranging from interrupt requests to data carrier detection. Starting from the left-most bit, the IRQ (Interrupt Request) is set whenever the ACIA wants to interrupt the CPU. This can happen for several reasons, such as when the received data register is full, the transmitter data register is empty, or the !DCD bit is set. Next, the PE (Parity Error) is set if the received parity bit doesn't match the locally generated parity for incoming data. The OVRN (Receiver Overrun) bit is set when new data overwrites old data that hasn't been read by the CPU, indicating data loss. The FE (Framing Error) flag comes into play when the received data is not correctly framed by start and stop bits.  After reading
After reading 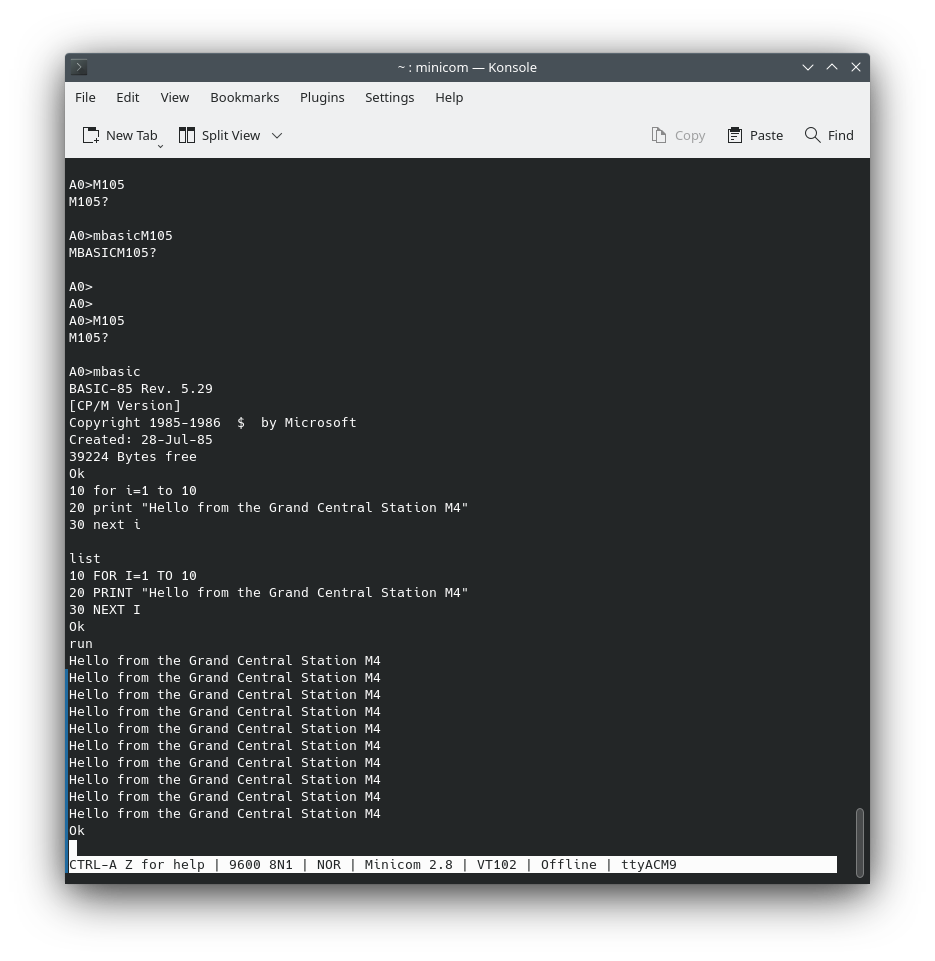


 Cheifet's talent lay in his ability to bridge the gap between the intricate, often intimidating world of technology and the average person. He recognized that, for many, the world of bits and bytes, processors and modems was a foreign landscape, but one that was becoming increasingly important to navigate. It was this recognition that drove Cheifet to break down complex topics into digestible, relatable segments. With a calm and steady demeanor, he approached each episode as an opportunity to empower his viewers, transforming intimidating jargon into clear and understandable language. Whether discussing the specifics of a new piece of software, the inner workings of a computer, or the broader implications of internet privacy, Cheifet acted as a translator, converting the technical into the practical. In this capacity, he played a pioneering role in tech communication. He understood that technology was not just for the experts; it was becoming a central part of everyone’s life, and thus everyone deserved to understand it. Cheifet saw the potential for technology to be a tool for widespread empowerment and sought to equip people with the knowledge they needed to harness that potential. Through "The Computer Chronicles," he demystified the computer revolution, making it approachable and accessible for viewers of all backgrounds. In doing so, he shaped the way an entire generation came to understand and interact with the technological world, emphasizing that technology was not just a subject for specialists, but a fundamental aspect of modern life that everyone could—and should—engage with.
Cheifet's talent lay in his ability to bridge the gap between the intricate, often intimidating world of technology and the average person. He recognized that, for many, the world of bits and bytes, processors and modems was a foreign landscape, but one that was becoming increasingly important to navigate. It was this recognition that drove Cheifet to break down complex topics into digestible, relatable segments. With a calm and steady demeanor, he approached each episode as an opportunity to empower his viewers, transforming intimidating jargon into clear and understandable language. Whether discussing the specifics of a new piece of software, the inner workings of a computer, or the broader implications of internet privacy, Cheifet acted as a translator, converting the technical into the practical. In this capacity, he played a pioneering role in tech communication. He understood that technology was not just for the experts; it was becoming a central part of everyone’s life, and thus everyone deserved to understand it. Cheifet saw the potential for technology to be a tool for widespread empowerment and sought to equip people with the knowledge they needed to harness that potential. Through "The Computer Chronicles," he demystified the computer revolution, making it approachable and accessible for viewers of all backgrounds. In doing so, he shaped the way an entire generation came to understand and interact with the technological world, emphasizing that technology was not just a subject for specialists, but a fundamental aspect of modern life that everyone could—and should—engage with. As the show journeyed through the years, its chronicles mirrored the seismic shift in global tech culture. In the early 1980s, when "The Computer Chronicles" began its broadcast, computers were predominantly seen as large, intimidating machines reserved for business, academia, scientific research, engineering, or the realm of enthusiastic hobbyists. They were more an anomaly than a norm in households. However, as the years progressed and the show continued to share, explain, and demystify each technological advancement, a noticeable transformation was underway. Computers evolved from being hefty, esoteric devices to compact, user-friendly, and essential companions in everyday life. This shift in tech culture was not solely about hardware evolution. The show also highlighted the software revolutions, the birth of the internet, and the early inklings of the digital society that we live in today. "The Computer Chronicles" documented the journey from a time when software was purchased in physical boxes to the era of digital downloads; from the era where online connectivity was a luxury to the age where it became almost as vital as electricity. The show captured the world's transition from disconnected entities to a globally connected network, where information and communication became instantaneous. Reflecting on the legacy of the show, it's evident that its influence transcended mere entertainment or education. It served as a compass, helping global viewers navigate the torrent of technological advancements. By chronicling the shift in tech culture, the show itself became an integral part of that transformation, shaping perceptions, bridging knowledge gaps, and fostering a sense of global camaraderie in the shared journey into the digital age. The show was more than just a television show; it was a comprehensive educational resource that was utilized in a variety of contexts. Schools, colleges, and community centers often integrated episodes of the show into their curricula to provide students with real-world insights into the fast-evolving landscape of technology. The detailed product reviews, software tutorials, and expert interviews that were a staple of the program served as valuable supplemental material for educators striving to bring technology topics to life in the classroom. In a period where textbooks could quickly become outdated due to the pace of technological change, "The Computer Chronicles" offered timely and relevant content that helped students stay abreast of the latest developments in the field.
As the show journeyed through the years, its chronicles mirrored the seismic shift in global tech culture. In the early 1980s, when "The Computer Chronicles" began its broadcast, computers were predominantly seen as large, intimidating machines reserved for business, academia, scientific research, engineering, or the realm of enthusiastic hobbyists. They were more an anomaly than a norm in households. However, as the years progressed and the show continued to share, explain, and demystify each technological advancement, a noticeable transformation was underway. Computers evolved from being hefty, esoteric devices to compact, user-friendly, and essential companions in everyday life. This shift in tech culture was not solely about hardware evolution. The show also highlighted the software revolutions, the birth of the internet, and the early inklings of the digital society that we live in today. "The Computer Chronicles" documented the journey from a time when software was purchased in physical boxes to the era of digital downloads; from the era where online connectivity was a luxury to the age where it became almost as vital as electricity. The show captured the world's transition from disconnected entities to a globally connected network, where information and communication became instantaneous. Reflecting on the legacy of the show, it's evident that its influence transcended mere entertainment or education. It served as a compass, helping global viewers navigate the torrent of technological advancements. By chronicling the shift in tech culture, the show itself became an integral part of that transformation, shaping perceptions, bridging knowledge gaps, and fostering a sense of global camaraderie in the shared journey into the digital age. The show was more than just a television show; it was a comprehensive educational resource that was utilized in a variety of contexts. Schools, colleges, and community centers often integrated episodes of the show into their curricula to provide students with real-world insights into the fast-evolving landscape of technology. The detailed product reviews, software tutorials, and expert interviews that were a staple of the program served as valuable supplemental material for educators striving to bring technology topics to life in the classroom. In a period where textbooks could quickly become outdated due to the pace of technological change, "The Computer Chronicles" offered timely and relevant content that helped students stay abreast of the latest developments in the field. In the annals of computing history, few microprocessors stand out as prominently as the
In the annals of computing history, few microprocessors stand out as prominently as the  During the late 1990s and early 2000s, as I delved into the foundational calculus studies essential for every engineering and computer science student, I invested in a TI-89. Acquiring it with the savings from my college job, this graphing calculator, driven by the robust 68k architecture, swiftly became an invaluable tool. Throughout my undergraduate academic journey, the TI-89 stood out not just as a calculator, but as a trusted companion in my studies. From introductory calculus to multivariate calculus to linear algebra and differential equations, my TI-89 was rarely out of reach while in the classroom.
During the late 1990s and early 2000s, as I delved into the foundational calculus studies essential for every engineering and computer science student, I invested in a TI-89. Acquiring it with the savings from my college job, this graphing calculator, driven by the robust 68k architecture, swiftly became an invaluable tool. Throughout my undergraduate academic journey, the TI-89 stood out not just as a calculator, but as a trusted companion in my studies. From introductory calculus to multivariate calculus to linear algebra and differential equations, my TI-89 was rarely out of reach while in the classroom.
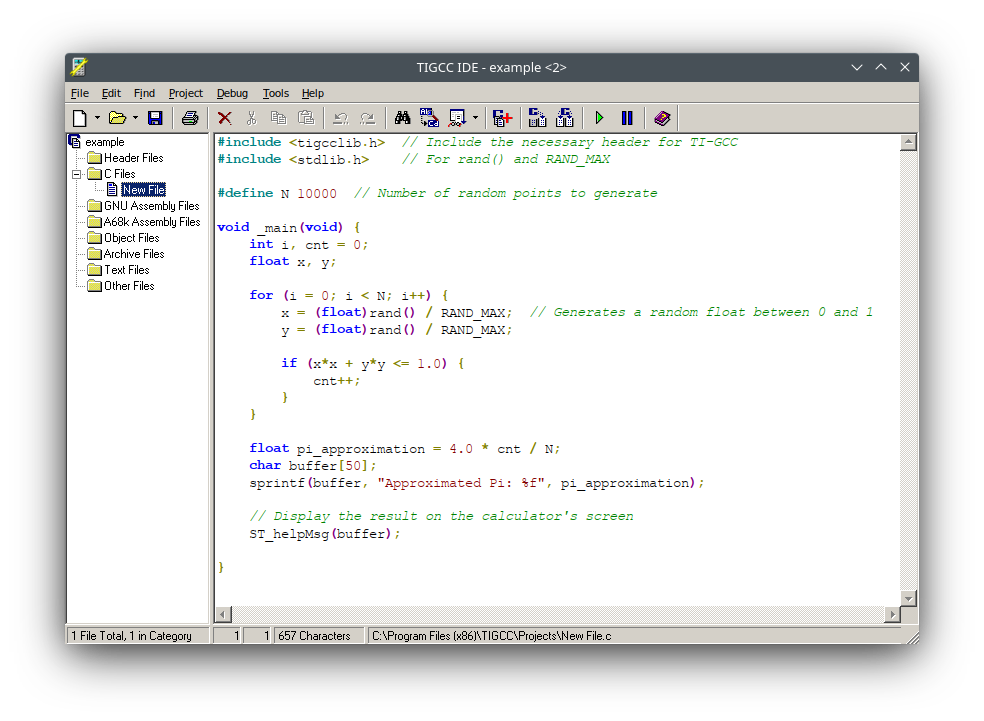
 The Texas Instruments TI-84 Plus graphing calculator has been a significant tool in the realm of
The Texas Instruments TI-84 Plus graphing calculator has been a significant tool in the realm of  The last step is running the 'Hello World' program on the TI-84+ calculator. The TI-84+ calculator interface has several buttons similar to a physical calculator, which are used to interact with the software. Here's how to execute the program:
The last step is running the 'Hello World' program on the TI-84+ calculator. The TI-84+ calculator interface has several buttons similar to a physical calculator, which are used to interact with the software. Here's how to execute the program: